REST Architecture
Client Server Architecture
Example with Explanation
Client-server architecture is a computer networking model in which client computers request and receive data or services from server computers.
Example 1: Imagine you are at a restaurant with a group of friends. You and your friends are the clients, and the servers are the waitstaff who take your orders and bring you food. You (the client) place an order with the server, who then goes to the kitchen to prepare the food. When the food is ready, the server brings it back to your table (the client).
Example 2: Now imagine you are at home and want to watch a movie on Netflix. In this scenario, your computer (or smart TV) is the client and the Netflix servers are the servers. You (the client) send a request to the Netflix servers to stream a particular movie. The Netflix servers then send the movie data back to your device (the client) so you can watch it.
Example 3: Imagine you are shopping online at an e-commerce website like Amazon. In this case, your computer (or smartphone) is the client and the Amazon servers are the servers. You (the client) browse the website and add items to your shopping cart. When you are ready to checkout, you submit your order to the Amazon servers (the server). The servers then process your payment and send the order confirmation back to your device (the client).
In a client-server architecture, one or more clients request resources or services from a central server. The client is the computer or device that initiates the request, and the server is the computer or device that responds to the request and provides the requested resources or services.
Here is an example of how a client-server architecture works:
-
A client computer needs to access a file that is stored on a server.
-
The client computer sends a request to the server to access the file.
-
The server receives the request and checks to see if the client has permission to access the file.
-
If the client has permission, the server retrieves the file and sends it back to the client.
-
The client receives the file and can now access it.
There are several advantages to using a client-server architecture:
-
Centralized resources: In a client-server architecture, the resources and services are provided by a central server, which makes it easier to manage and update them.
-
Scalability: A client-server architecture can be easily scaled up or down to meet the changing needs of an organization.
-
Security: A client-server architecture allows for better security, as the server can be configured to only allow certain clients to access certain resources or services.
-
Reliability: A client-server architecture can be more reliable, as the server can be configured to automatically failover to a backup server if the primary server goes down.
There are also some disadvantages to using a client-server architecture:
-
Dependency on the server: If the server goes down, the clients will not be able to access the resources or services they need.
-
Network latency: The client-server architecture relies on a network connection, which can introduce latency and slower performance.
-
Cost: Setting up and maintaining a client-server architecture can be more expensive than other types of architectures.
simple diagram that illustrates a client-server architecture:
+------------+
| |
| Client |
| |
+------------+
|
| request
|
+------------+
| |
| Server |
| |
+------------+
|
| response
|
+------------+
| |
| Client |
| |
+------------+
or, ________________________________________________________________
Client Server
---- ----
| | | |
| | request ----------> | |
| | | |
| | response <---------- | |
| | | |
---- ----
In this diagram, the client sends a request to the server, and the server responds with a response. The client and server may communicate using a variety of protocols, such as HTTP, HTTPS, FTP, or SSH.
The client-server architecture is a common design pattern that is used to build many types of software applications, including web applications, mobile apps, and desktop applications. It is also used in distributed computing systems, where multiple clients can connect to a single server or multiple servers.
The main advantage of the client-server architecture is that it allows the client and server to communicate and exchange data in a decentralized manner, which makes it easy to scale and maintain the system. It also allows for better security, as the client and server can be designed to use secure communication protocols and authentication mechanisms to protect against unauthorized access.
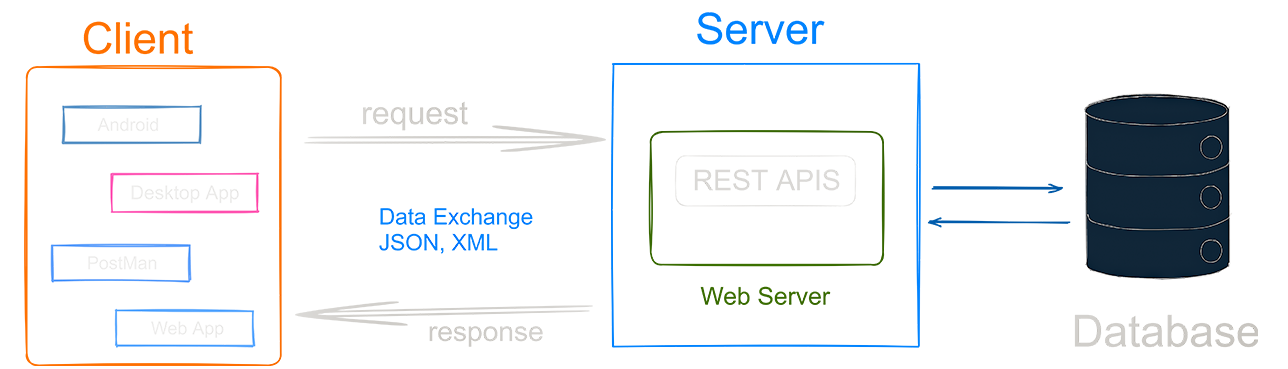
Rest
Example with Explanation
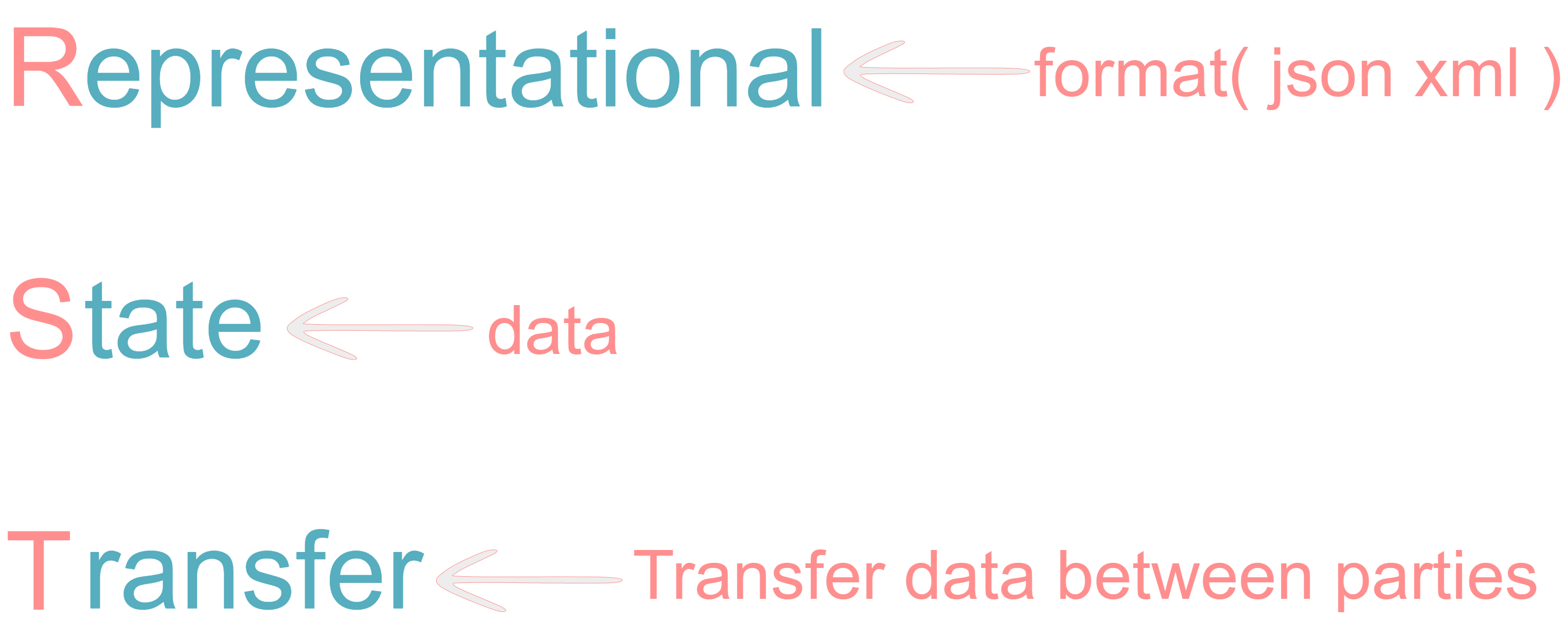
REST (Representational State Transfer) is a software architectural style that defines a set of constraints and properties for creating web services. It is based on the idea of representing resources, such as data or functionality, in a uniform and predictable way. RESTful web services use HTTP methods, such as GET, POST, PUT, DELETE, etc., to perform operations on resources.
+------------+ +-------------+ +------------+
| Client | | Server | | Database |
+------------+ +-------------+ +------------+
| | |
| | |
| GET /resources/1 | |
| ---------------------------> |
| | |
| | Resource 1 |
| | ----------------->|
| | |
| | |
| | |
| | HTTP 200 OK |
| | <------------------|
| | |
| | |In this diagram:
- The client sends an HTTP request to the server to retrieve a resource.
- The server receives the request and processes it, possibly accessing a database to retrieve the requested resource.
- The server responds to the client with an HTTP response, including the requested resource in the body of the message.
RESTful web services can be used to create APIs (Application Programming Interfaces) that allow different systems to communicate with each other over the web. These APIs can be accessed by clients using HTTP requests and responses, making it easy to build distributed systems that can be accessed from multiple devices or platforms.
Imagine you have a to-do list application that stores and retrieves tasks from a database. The database contains a list of tasks, each with a unique identifier (ID), a description, and a status (e.g. "completed" or "pending").
To retrieve a list of tasks from the database, you could send a GET request to a URL that represents the collection of tasks (e.g. https://example.com/tasks (opens in a new tab)). The server would then return a list of tasks in the body of the response, possibly in a format like JSON or XML.
To add a new task to the database, you could send a POST request to the same URL, with the task details in the request body. The server would then create a new task in the database and return the ID of the new task in the response.
To update an existing task, you could send a PUT request to a URL that represents a specific task (e.g. https://example.com/tasks/123 (opens in a new tab)), with the updated task details in the request body. The server would then update the task in the database and return a response indicating that the update was successful.
Finally, to delete a task from the database, you could send a DELETE request to the URL that represents the task (e.g. https://example.com/tasks/123 (opens in a new tab)). The server would then delete the task from the database and return a response indicating that the deletion was successful.
This is just a simple example, but it illustrates how RESTful web services can be used to perform CRUD operations on a database using HTTP methods.
REST Constraints
Example with Explanation
REST, or Representational State Transfer, is a software architectural style that defines a set of constraints to be used for creating web services. The purpose of REST is to provide a standard way of accessing resources that are available on the web, using HTTP methods such as GET, POST, PUT, DELETE, and so on.
Here are the six constraints of REST, along with a brief explanation of each:
- Client-server architecture: The client-server architecture constraint separates the client, which makes requests to the server, from the server, which responds to those requests. This separation allows for the client and server to evolve independently of one another.
For example, consider a web-based email service. The client (e.g., your web browser) makes requests to the server (e.g., the email service's servers) to send and retrieve emails. The server responds to those requests by sending the requested emails back to the client. The client and server are separate entities, allowing the email service to update its servers without affecting the client (e.g., your web browser) and vice versa.
- Statelessness: The statelessness constraint means that the server does not store any state about the client between requests. This means that each request from the client must contain all the information necessary for the server to understand and respond to the request.
For example, consider a weather website that allows you to check the forecast for a specific city. Each time you make a request to the server to get the forecast for a particular city, the server does not store any information about your previous requests. Instead, the server responds to each request based solely on the information contained in that request.
- Cacheability: The cacheability constraint indicates to the client whether a response can be cached or not. This allows for efficient use of resources and can improve the performance of the system.
For example, consider a news website that displays the latest headlines. The server may include cacheability information in its responses, indicating that the headlines can be cached for a certain period of time. This means that the client (e.g., your web browser) can store a copy of the headlines locally and display them to you without needing to make a new request to the server every time you refresh the page.
- Layered system: The layered system constraint means that the client does not need to know the details of how the request is being processed. It can simply send a request to the server, and the server can pass the request on to other layers as necessary to fulfill the request.
For example, consider a shopping website that allows you to search for products and add them to your cart. When you make a request to search for a particular product, the server may pass that request on to a search engine layer, which processes the request and returns the results to the server. The server then formats the results and sends them back to the client. The client does not need to know the details of how the search was performed; it just sends the request and receives the results.
- Code on demand (optional): The code on demand constraint allows the server to send code to the client that the client can execute. This can be used to extend the functionality of the client.
For example, consider a website that allows you to customize the look and feel of the site by choosing from a selection of pre-designed themes. The server may send code to the client (e.g., your web browser) that changes the colors and fonts of the site based on the theme you choose. This allows the server to provide additional functionality to the client without the client needing to download and install any software.
- Uniform interface: The uniform interface constraint means that the interface between the client and server should be uniform, meaning that all resources should be accessed in the same way, using the same set of methods (e.g., GET, POST, PUT, DELETE).
For example, consider a website that allows you to search for products and add them to your cart. The server may provide a uniform interface for accessing products, allowing you to search for products using a GET request to the /products endpoint, and add products to your cart using a POST request to the /cart endpoint.
GET /tasks
Returns a list of all tasks
POST /tasks
Creates a new task
GET /tasks/{id}
Returns the task with the specified ID
PUT /tasks/{id}
Updates the task with the specified ID
DELETE /tasks/{id}
Deletes the task with the specified ID